Lược dịch Designing Data-Intensive Applications — Phần I, chương 1
Chương 1 — Tính tin cậy, dễ mở rộng và bảo trì của ứng dụng.
“Internet đã được phát triển tốt đến mức hầu hết mọi người liên tưởng nó giống một nguồn tài nguyên thiên nhiên dồi dào như Thái Bình Dương, hơn là một thứ do con người tạo ra. Lần cuối có một công nghệ quy mô lớn tương tự mà không gặp phải lỗi là khi nào?”
— Alan Kay, trong buổi phỏng vấn với Dr Dobb’s Journal (2012)
Nhiều hệ thống ngày nay chuyên sâu về dữ liệu (data-intensive), trái ngược với chuyên sâu về tính toán (compute-intensive). Vấn đề của những ứng dụng ấy thường đến từ xử lý hiệu quả những dữ liệu có độ lớn và độ phức tạp cao. Yêu cầu được đặt ra cho chúng là:
- Lưu trữ dữ liệu để bản thân chúng, hoặc các chương trình khác gọi lại (databases).
- Ghi nhớ lại kết quả của những tính toán nặng để tăng tốc độ đọc (caches).
- Hỗ trợ tìm kiếm dữ liệu linh hoạt (search indexs).
- Gửi message tới một process khác, rồi xử lý một cách bất đồng bộ (stream processing).
- Định kỳ Crunch một lượng lớn dữ liệu có tích luỹ qua thời gian (batch processing).
Chương này sẽ bàn chi tiết về các đặc tính Tin Cậy, Mở Rộng, Bảo Trì của một hệ thống chuyên sâu về dữ liệu.
Suy nghĩ về các hệ thống dữ liệu (Data Systems)
Ngày nay có nhiều công cụ dành cho lưu trữ và xử lý dữ liệu. Chúng có thể được sử dụng trong nhiều mục đích khác nhau, vì vậy thật khó khăn khi cố gắng nhét chúng vào một category truyền thống nào đó. Ví dụ: Redis là một dạng datastore, nhưng cũng có thể dùng như một message-queue. Và một message-queue như Kafka có thể dùng như một database.
Các ứng dụng ngày nay ngày càng phức tạp, hiếm có một công cụ đơn lẻ có thể giải quyết yêu cầu được đặt ra. Thay vì đó, ứng dụng sẽ là tập hợp của những công cụ giải quyết từng vấn đề riêng lẻ một cách tốt nhất và liên kết chặt chẽ với nhau. Ví dụ, bạn có thể có một ứng dụng sử dụng Memcached cho caching, ElasticSearch cho nhu cầu full-text search server đứng độc lập và có nhiệm vụ đồng bộ cache và index với DB chính. Hình dưới đây mô tả các thành phần mà một hệ thống thường có:

Cuốn sách sẽ tập trung vào cách tính chất:
- Tính tin cậy — Reliability: Hệ thống nên tiếp tục hoạt động chính xác (thực hiện đúng chức năng ở mức hiệu suất mong muốn) ngay cả khi đối mặt với nghịch cảnh (lỗi phần cứng hoặc phần mềm và thậm chí là lỗi của con người).
- Có khả năng mở rộng — Scalability: Khi hệ thống tăng trường (về lượng dữ liệu, lượng truy cập hoặc mức độ phức tạp) thì cần có những cách hợp lý để xử lý sự tăng trưởng đó.
- Tính bảo trì — Maintainability: Theo thời gian, nhiều người khác nhau sẽ tham gia vào hệ thống, và tất cả họ sẽ phải có thể làm việc trên đó một cách hiệu quả nhất.
Tính tin cậy — Reliability:
Khi một hệ thống được cho là tin cậy khi nó thoả mãn những yêu cầu sau:
- Hoạt động đúng như những gì được kỳ vọng.
- Hoạt động tốt ngay cả khi có lỗi từ người dùng hoặc sử dụng chúng một cách không mong muốn.
- Hiệu suất của nó phải đủ tốt ở những trường hợp được dự kiến trước.
Tổng hợp những yêu cầu trên vào trong một câu nói, có thể phát biểu là “tiếp tục hoạt động chính xác, ngay cả khi gặp sự cố.” Những hệ thống đạt được tiêu chí này có thể gọi là fault-tolerant hoặc resilient. Lưu ý rằng, không thể kỳ vọng hệ thống có thể chịu đựng mọi loại lỗi, cũng như giảm xác suất xảy ra lỗi bằng 0 vì như vậy là thiếu thực tế. Thay vì đó, tốt nhất là thiết kế các cơ chế chống lỗi để ngăn ngừa các lỗi xảy ra theo dây chuyền.
Chúng ta cũng có thể kiểm tra tính tin cậy của hệ thống bằng cách kích hoạt lỗi một cách có chủ ý. Ví dụ, ngẫu nhiên dừng hoạt động một số process mà không báo trước. Kinh nghiệm cho thấy nhiều lỗi nghiêm trọng xảy ra là do xử lý lỗi kém. Bằng cách cố ý gây ra lỗi, bạn có thể đảm bảo rằng cơ chế chịu lỗi liên tục được kiểm tra, điều này có thể làm tăng sự tin tưởng rằng lỗi sẽ được xử lý chính xác khi chúng xảy ra một cách tự nhiên. Netflix Chaos Monkey là một ví dụ về phương pháp này.
Các loại lỗi ảnh hưởng đến tính tin cậy của hệ thống:
1. Lỗi phần cứng
Lỗi phần cứng luôn là những lý do chúng ta thường nghĩ đến đầu tiên. Đây có thể là những lỗi như ổ đĩa hay RAM bị crash, network mất kết nối hoặc thậm chí là cả mất điện. Các đĩa cứng có thời gian trung bình bị gặp lỗi là khoảng 10 đến 50 năm. Do đó, trên một cụm data center có 10.000 ổ đĩa, chúng ta có thể suy đoán rằng trung bình sẽ có 1 ổ đĩa sẽ chết mỗi ngày.
Thậm chí những nền tảng đám mây như AWS cũng có thể gặp lỗi mà không hề có dấu hiệu nào thông báo trước. Phương pháp có những thành phần backup cho các phần cứng kể trên. Cách tiếp cận này không thể ngăn chặn hoàn toàn các sự cố phần cứng gây ra lỗi, nhưng nó có thể giữ cho hệ thống chạy không bị gián đoạn trong nhiều trường hợp.
2. Lỗi phần mềm
Nếu như các lỗi phần cứng thường xảy ra độc lập (không theo dây chuyền) và ít ảnh hưởng lẫn nhau. Hiếm có khi nào hàng loạt phần cứng cùng hỏng một lúc. Thế nhưng lỗi phần mềm thì khác, nó khó nhận biết hơn và cũng có mối tương quan giữa các node trong hệ thống chặt chẽ hơn. Cho nên chúng thường sẽ dẫn tới những lỗi nghiêm trọng hơn hơn là lỗi phần cứng. Các VD của lỗi thuộc về phần mềm như:
- Hệ thống xảy ra lỗi khi gặp bad input. VD: lỗi Leap Second trong nhân Linux
- Một proccess chiếm dụng toàn bộ resource, gây ra treo hệ thống.
- Một services dựa vào một nguồn tài nguyên nào đó không ổn định (chậm trễ hoặc có thể trả về kết quả sai).
- Lỗi hàng loạt (cascading failures), khi mà một lỗi nhỏ có thể dẫn tới những lỗi ở một thành phần khác, từ đó gây ra các lỗi tiếp theo.
Các loại lỗi phần mềm thường tồn tại trong một thời gian dài cho đến khi chúng bị phát hiện bởi một tình huống bất thường không ngờ tới. Trong những trường hợp đó, có thể thấy rằng phần mềm đang đưa ra một số giả định về môi trường của nó là đúng, nhưng cuối cùng nó cũng không còn đúng nữa vì một lý do nào đó. Không có một giải pháp nhanh chóng nào cho các lỗi thuộc phần mềm. Nhưng những giải pháp đơn lẻ sẽ có thể giúp ích như:
- Các biện pháp kiểm thử.
- Cô lập hoặc cho phép các process có thể bị crash và khởi động lại.
- Đo lường, đánh giá và phân tích trên môi trường production.
3. Lỗi con người
Con người là những người xây dựng và vận hành hệ thống. Ngay cả những người cẩn thận nhất cũng có thể có những lúc mắc lỗi. Ví dụ như một nghiên cứu về các dịch vụ internet lớn cho thấy lỗi cấu hình hệ thống của người vận hành là nguyên nhân hàng đầu cho các sự cố ngừng hoạt động, trong khi lỗi phần cứng chỉ đóng vai trò trong 10–25%. Vậy để giải quết những lỗi đến từ yếu tố con người thì sau đây là một số giải pháp:
- Thiết kế một hệ thống giảm thiểu cơ hội xảy ra lỗi. VD có một well-designed abstractions, APIs để dễ dàng làm theo chuẩn đã có và làm “nản lòng” những hành vi dẫn tới lỗi.
- Tách rời những nơi mà mọi người mắc lỗi nhiều nhất từ những nơi mà họ có thể gây ra thất bại. Đặc biệt, cung cấp các môi trường sandbox đầy đủ tính năng nơi mọi người có thể thử nghiệm một cách an toàn, sử dụng dữ liệu thực mà không ảnh hưởng đến người dùng thực.
- Xây dựng môi trường test ở nhiều cấp độ, từ unit test cho đến integration test cho toàn hệ thống, và cả manual test. Automation test cũng là cách tốt để kiểm tra những edge case bất thường hiếm khi phát sinh trong những tình huống thông thường.
- Cho phép phục hồi nhanh chóng và dễ dàng từ các lỗi của con người, nhằm giảm thiểu tác động trong trường hợp lỗi. Ví dụ: nhanh chóng khôi phục các thay đổi cấu hình, rollout code từng phần (để mọi lỗi không mong muốn chỉ ảnh hưởng đến một tập nhỏ người dùng) và có các công cụ để khôi phục dữ liệu (trong trường hợp lỗi xảy ra khiến dữ liệu không chính xác).
- Xây dựng các phương pháp monitor chi tiết và rõ ràng như đo performance hay tỉ lệ lỗi. Khi một vấn đề xảy ra, các metrics có thể rất có giá trị trong phán đoán vấn đề.
- Xây dựng các biện pháp thực hành và training tốt cũng là một khía cạnh quan trọng.
Tóm lại, tính tin cậy là rất quan trọng, không chỉ trong các lĩnh vực như hàng không và điện hạt nhân, mà còn cả phát triển phần mềm. Lỗi trong các ứng dụng làm giảm năng suất, tổn thất chi phí cũng như uy tín và thậm chí gặp cả nguy cơ pháp lý (như trong trường hợp số liệu được báo cáo không chính xác).
Tính dễ mở rộng — Scalability:
Ngay cả một hệ thống đang chạy ổn định thời điểm hiện tại, không có nghĩa nó sẽ chạy tốt trong tương lai. Một trong những lý do là gia tăng tải của hệ thống, ví dụ hệ thống tăng từ 10K CCU tới 100K, 1M, 10M CCU. Hoặc phải xử lý nhiều dữ liệu hơn so với trước đây. Scalability là thuật ngữ để mô tả một hệ thống có thể đối phó với lượng tải tăng trong tương lai.
1. Mô tả lượng tải
Đầu tiên chúng ta phải mô tả được tình trạng tải hiện tại của hệ thống, từ đó mới có thể trả lời được những câu hỏi về tăng trưởng tương lai. Những thông số đó được gọi là load parameters. Chúng dựa trên kiến trúc của ứng dụng. Ví dụ để mô tả load của webserver, ta dùng request per seconds, database sẽ là ratio của đọc/ghi dữ liệu, cache sẽ là lượng hit cache… Khi đã có những số liệu cụ thể, ta có thể dễ dàng đưa ra phương án scaling cho hệ thống tốt hơn (ví dụ với bài toán của Twitter).
2. Mô tả hiệu năng
Một khi bạn đã mô tả tải trên hệ thống của mình, bạn có thể hiểu sâu những gì xảy ra khi tải tăng lên. Thông thường sẽ có 2 câu hỏi nảy ra:
- Nếu ta giữ nguyên resource hệ thống (CPU, RAM, băng thông, …), hệ thống của chúng ta sẽ bị ảnh hưởng như thế nào?
- Khi tăng tải lên, chúng ta sẽ cần bao nhiêu resource để giữ performance không bị ảnh hưởng?
Trong xử lý batching, chúng ta thường sẽ quan tâm đến con số thông lượng (throughput — số record xử lý trong 1 giây hay tổng thời gian xử lý trên 1 tập data xác định). Còn ở các hệ thống online (Online processing), thường thời gian phản hồi sẽ được chú ý tới (thời gian giữa gửi và nhận request).
Tuy nhiên thời gian phản hồi chưa thực sự phản ánh toàn bộ performance của hệ thống. Tuy nhiên, giá trị trung bình của nó không phải là một số liệu thực sự tốt nếu bạn muốn biết thời gian phản hồi “thông thường”, bởi vì nó không cho bạn biết có bao nhiêu người dùng thực sự gặp phải sự chậm trễ đó.
Thay vào đó ta nên sử dụng tỉ lệ phần trăm. Nếu lấy danh sách thời gian phản hồi và sắp xếp nó từ nhanh nhất đến chậm nhất, thì trung vị (median) là điểm giữa. Trung vị còn được gọi là phân vị thứ 50, và đôi khi được viết tắt là p50. Để thấy được những phản hồi chậm, bạn có thể nhìn vào những phần trăm cao hơn: phần trăm thứ 95, 99 và 99,9 thường là phổ biến (viết tắt là P95, P99 và P99.9). Chúng là các ngưỡng thời gian phản hồi mà tại đó 95%, 99% hoặc 99,9% yêu cầu nhanh hơn ngưỡng cụ thể đó. Ví dụ: nếu thời gian phản hồi của phân vị thứ 95 là 1,5 giây, điều đó có nghĩa là 95 trong số 100 yêu cầu mất ít hơn 1,5 giây và 5 yêu cầu mất hơn 1,5 giây.
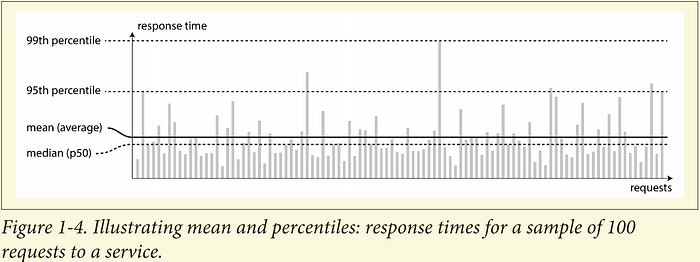
Phần trăm thời gian phản hồi cao, còn được gọi là độ trễ đuôi, là rất quan trọng vì chúng ảnh hưởng trực tiếp đến trải nghiệm dịch vụ của người dùng.
Ví dụ: Amazon mô tả các yêu cầu về thời gian phản hồi cho các dịch vụ nội bộ theo P99,9, nghĩa là 1 trong 1.000 request sẽ phản hồi chậm hơn mức yêu cầu. Điều này là do những khách hàng nhận phản hồi chậm nhất thường là những người có nhiều dữ liệu nhất trên tài khoản của họ vì họ đã thực hiện nhiều giao dịch mua — tức là, họ là những khách hàng có giá trị nhất. Điều quan trọng là giữ cho những khách hàng đó hài lòng bằng cách đảm bảo trang web nhanh chóng cho họ: Amazon cũng đã quan sát thấy rằng thời gian phản hồi tăng 100 mili giây làm giảm doanh số bán hàng xuống 1% và những người khác báo cáo rằng tốc độ chậm 1 giây làm giảm 16% sự hài lòng của khách hàng. Mặt khác, việc tối ưu hóa P99,99 (1 trong 10.000 request chậm nhất) được cho là đắt đỏ và không mang lại lợi ích đáng kể cho Amazon. Việc giảm thời gian phản hồi ở các tỷ lệ phần trăm rất cao là rất khó vì chúng dễ bị ảnh hưởng bởi các sự kiện ngẫu nhiên nằm ngoài tầm kiểm soát của bạn.
Các tỉ lệ phần trăm (P95, P99,…) còn sử dụng trong Service Level Objectives (SLOs) và Service Level Agreements (SLAs), các hợp đồng xác định hiệu suất dự kiến và tính khả dụng của một dịch vụ. Ví dụ, SLAs có thể tuyên bố dịch vụ đang hoạt động ổn định khi đạt P99 ở độ trễ phản hồi là 200ms. Các chỉ số này đặt ra kỳ vọng cho khách hàng về dịch vụ và cho phép khách hàng yêu cầu hoàn lại tiền nếu SLA không được đáp ứng.
Những chỉ số này rất quan trọng. Chỉ cần một cuộc gọi chậm để làm cho toàn bộ yêu cầu của người dùng cuối chậm lại. Ngay cả khi chỉ một tỷ lệ nhỏ các sub-request bị chậm, request của người dùng cuối sẽ bị chậm theo (gọi là hiệu ứng khuếch đại độ trễ đuôi).
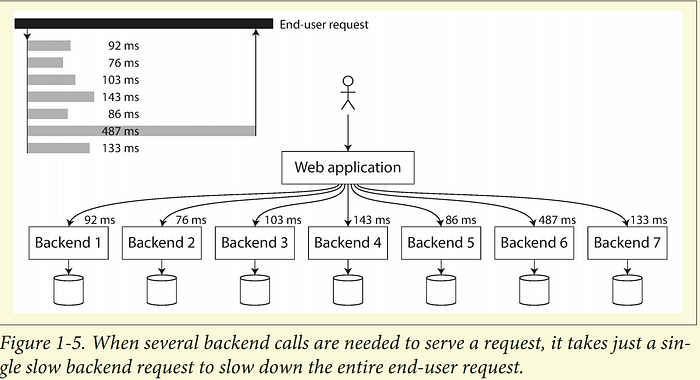
3. Các phương pháp đối phó với tải cao
Làm thế nào để chúng ta duy trì hiệu suất tốt ngay cả khi các thông số tải của chúng ta tăng lên một số lượng nhất định? — Một kiến trúc thích hợp cho một mức tải nhất định thì có thể phải chịu được gấp 10 lần mức tải đó.
Có hai dạng mở rộng là mở rộng về năng lực (scaling-up hay vertical scaling — mở rộng theo chiều dọc, tức là nâng cấp lên máy cấu hình mạnh hơn) và mở rộng về quy mô (scaling out hay horizonal scaling — mở rộng theo chiều ngang, phân phối tải trên nhiều máy yếu hơn). Trong thực tế, các kiến trúc tốt thường bao gồm hỗn hợp các phương pháp tiếp cận, ví dụ: sử dụng một số máy chủ mạnh vẫn có thể dễ dàng quản lý và rẻ hơn một số lượng lớn các máy chủ nhỏ hơn.
Kiến trúc của các hệ thống lớn thường rất cụ thể cho từng loại ứng dụng. Bởi vì vấn đề có thể đến từ khối lượng đọc hoặc ghi lớn, khối lượng của dữ liệu cần lưu trữ, độ phức tạp dữ liệu ấy, yêu cầu về thời gian phản hồi, cách thức truy cập, … hoặc (phổ biến hơn cả) là hỗn hợp của tất cả những thứ kể trên và còn thêm nhiều yếu tố khác nữa. Ví dụ: một hệ thống được thiết kế để xử lý 100K request mỗi giây có kích thước mỗi request là 1 KB, sẽ rất khác so với hệ thống được thiết kế cho 3 request mỗi phút nhưng mỗi request lại có kích thước 2 GB — mặc dù hai hệ thống có cùng throughput.
Tính bảo trì — Maintainability:
Chúng ta đều biết rằng phần lớn chi phí của phát triển phần mềm không nằm trong quá trình xây dựng ban đầu mà là trong quá trình bảo trì , sửa lỗi, giữ cho hệ thống của nó hoạt động, điều tra lỗi, nâng cấp và sửa đổi nó cho các trường hợp sử dụng mới, trả nợ kỹ thuật và thêm các tính năng mới.
Hầu hết mọi người đều không hứng thú làm việc trên Legacy System — khi nó liên quan đến những phần sửa lỗi, phần việc lỗi thời của người khác. Mọi như vậy (Legacy System), đều khó chịu theo cách riêng của nó và vì vậy rất khó để đưa ra các cách thức chung để giải quyết chúng.T uy nhiên, chúng ta có thể thiết kế phần mềm để giảm thiểu sự cố trong quá trình bảo trì, ba nguyên tắc đó là:
- Tính hoạt động: Làm hệ thống đơn giản với đội vận hành có thể giữ nó hoạt động trơn tru.
- Tính đơn giản: giúp hệ thống dễ hiểu với ngay cả các kỹ sư mới.
- Khả năng phát triển: Giúp các kỹ sư dễ dàng thực hiện thay đổi trong tương lai, kể cả các yêu cầu thay đổi không lường trước được. Hay còn được gọi là khả năng mở rộng, khả năng sửa đổi hoặc tính mềm dẻo.
Cùng đi sâu hơn vào từng đặc tính này:
Khả năng vận hành: Giúp vận hành trở nên dễ dàng hơn
“Các hoạt động tốt thường có thể khắc phục được những hạn chế của phần mềm xấu (hoặc chưa hoàn chỉnh), nhưng phần mềm tốt không thể chạy tốt với việc vận hành kém”.
Các nhóm vận hành rất quan trọng để giữ cho một hệ thống phần mềm hoạt động trơn tru. Một nhóm vận hành tốt thường chịu trách nhiệm về những việc sau, và còn hơn thế nữa:
- Theo dõi tình trạng của hệ thống và nhanh chóng khôi phục khi xảy ra lỗi.
- Truy vết được nguyên nhân sự cố.
- Giữ cho phần mềm được cập nhật, bao gồm các bản vá security.
- Theo dõi các hệ thống khác nhau ảnh hưởng đến nhau như thế nào để có thể tránh được một thay đổi có vấn đề trước khi nó gây ra thiệt hại.
- Dự đoán được các vấn đề trong tương lai và giải quyết chúng trước khi chúng có thể xảy ra (ví dụ: lên kế hoạch capacity).
- Thiết lập các phương pháp và công cụ tốt để triển khai, quản lý cấu hình…
- Thực hiện các nhiệm vụ bảo trì phức tạp, chẳng hạn như di chuyển cluster.
- Duy trì tính bảo mật của hệ thống khi thay đổi cấu hình.
- Xác định các quy trình giúp cho cách vận hành có thể dự đoán được và giữ cho môi trường production ổn định.
- Lưu giữ kiến thức của tổ chức về hệ thống, ngay cả khi có những đến hoặc rời đi.
Khả năng vận hành tốt có nghĩa là thực hiện các nhiệm vụ trên dễ dàng, cho phép thành viên nhóm tập trung nỗ lực của họ vào các hoạt động có giá trị cao. Hệ thống dữ liệu có thể thực hiện nhiều việc khác nhau để giúp các tác vụ thường ngày trở nên dễ dàng, bao gồm:
- Cung cấp hiển thị giám sát của hệ thống tốt.
- Hỗ trợ tốt cho việc tự động hóa và tích hợp với các công cụ tiêu chuẩn.
- Tránh phụ thuộc vào từng node riêng lẻ (cho phép đưa 1 node ra khỏi hệ thống mà không có gián đoạn xảy ra).
- Cung cấp tài liệu tốt và mô hình hoạt động dễ hiểu (“Nếu tôi làm X, thì Y sẽ xảy ra”)
- Cung cấp hành vi mặc định tốt, nhưng cũng cho phép quản trị viên tự do ghi đè các giá trị mặc định khi cần.
- Tự phục hồi nếu thích hợp, đồng thời cung cấp cho quản trị viên quyền kiểm soát thủ công đối với trạng thái hệ thống khi cần thiết.
- Thể hiện hành vi có thể đoán trước, giảm thiểu bất ngờ.
Tính đơn giản: Quản lý sự phức tạp
Các dự án phần mềm ngày càng trở nên phức tạp, đặc biệt là với những hệ thống lớn. Một dự án bị sa lầy vào sự phức tạp đôi khi được mô tả như một quả bóng bùn lớn (Big Ball of Mud).
Khi sự phức tạp khiến việc bảo trì trở nên khó khăn, ngân sách và thời gian biểu thường bị vượt quá khả năng cho phép. Trong một phần mềm phức tạp, cũng có nhiều nguy cơ phát sinh lỗi hơn khi thực hiện các thay đổi: khi hệ thống khó hiểu với đội ngũ phát triển, các giả định ngầm, hệ quả và các tương tác không mong muốn dễ bị bỏ qua hơn. Ngược lại, giảm độ phức tạp sẽ cải thiện đáng kể khả năng bảo trì của phần mềm, và do đó tính đơn giản phải là mục tiêu chính cho các hệ thống chúng ta xây dựng.
Làm đơn giản hệ thống không nhất thiết là cắt giảm chức năng của nó. Sự phức tạp được định nghĩa là một sự không mong muốn xảy ra trong quá trình phát triển nằm ngoài những vấn đề mà phần mềm cần giải quyết (mà người dùng thấy được).
Một trong những công cụ tốt nhất để loại bỏ sự phức tạp ngẫu nhiên là tính trừu tượng (abstraction). Một sự trừu tượng tốt có thể che các chi tiết triển khai đằng sau một giao diện dễ hiểu và có thể được sử dụng lại cho một loạt các ứng dụng khác nhau. Việc tái sử dụng này không chỉ giảm khối lượng công việc lặp lại mà còn dẫn đến phần mềm chất lượng cao hơn, vì những cải tiến chất lượng trong lớp trừu tượng được áp dụng cho các ứng dụng kế thừa nó.
Khả năng phát triển: Khiến thay đổi trở nên dễ dàng
Các hệ thống phần mềm luôn biến đổi liên tục. Sự dễ dàng mà bạn có thể sửa đổi hệ thống dữ liệu và điều chỉnh nó theo các yêu cầu thay đổi, được liên kết chặt chẽ với tính đơn giản và tính trừu tượng của nó: các hệ thống đơn giản và dễ hiểu thường dễ sửa đổi hơn các hệ thống phức tạp. Những công cụ để quản lý và làm hệ thống linh hoạt hơn là quy trình Agile, TDD, … Nhưng vì đây là một ý tưởng quan trọng, nên ta sẽ sử dụng một từ khác để chỉ sự linh hoạt ở cấp độ hệ thống dữ liệu: khả năng phát triển (evolvability).
Tổng kết
Chương này cung cấp một số cách suy nghĩ cơ bản của các ứng dụng chuyên sâu về dữ liệu. Những nguyên tắc sẽ đi sâu vào chi tiết kỹ thuật ở những chương sau.
Một ứng dụng phải đáp ứng các yêu cầu khác nhau để trở nên hữu ích. Có các yêu cầu về mặt chức năng (những gì nó nên làm, chẳng hạn như cho phép dữ liệu được lưu trữ, truy xuất, tìm kiếm và xử lý theo nhiều cách khác nhau) và một số yêu cầu phi chức năng (các thuộc tính chung như bảo mật, độ tin cậy, tuân thủ, khả năng mở rộng, tính tương thích và khả năng bảo trì) . Trong chương này, cũng đã thảo luận về những đặc tính đó.
